
苹果日前发表的一篇新研究报告 The Illusion of Thinking,对当前备受期待的 AI 推理模型泼下一盆冷水。 这份研究指出,当大型推理模型(Large Reasoning Models, LRM)面对愈加复杂的逻辑难题时,竟然会「彻底崩溃」,甚至选择中途放弃解题。
应对简单题目表现不及 LLM
根据这份研究,尽管 OpenAI o1 与 o3、DeepSeek R1、Claude 3.7 Sonnet Thinking 和 谷歌 Gemini Flash Thinking 等模型在中等难度题目中表现不错,但在简单题目的表现却比 LLM 更差。 一旦题目难度上升,这些模型竟然会完全「崩溃」,准确率降至零,并主动停止推理。
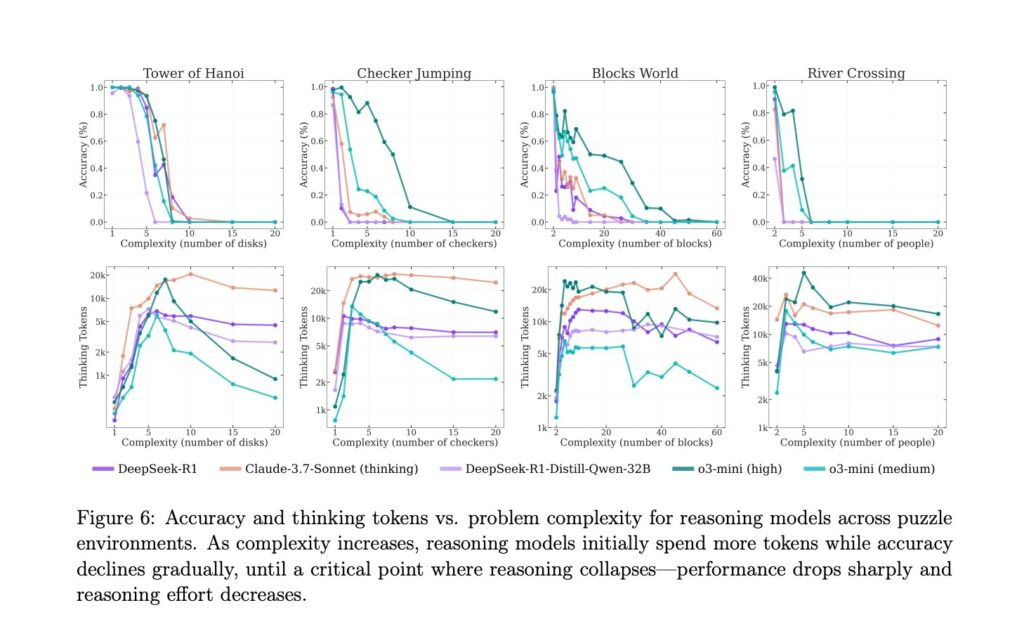

研究使用的测试题目,包括知名的Tower of Hanoi(河内塔)、跳棋、运河渡河问题(如狐狸、鸡与谷物的经典题型)与积木堆栈,这些都是人类在数学课上常见的经典逻辑游戏。 照理说,一旦掌握解法后,即使增加元素也只是重复应用逻辑。 但这些 LRM 模型却在进行到一定复杂度时完全崩解。
愈难愈不想「思考」
研究人员发现一个令人费解的现象:当题目难度增加,这些模型原本会投入更多思考资源(token),但一旦接近其极限门槛时,模型反而减少推理努力,甚至直接「放弃思考」。 即使研究人员提供了算法提示,让模型只需照步骤执行,准确率依然无明显改善。
研究如此指出:「所有推理模型在面对复杂度上升时,都呈现类似的表现模式:准确率逐步下降,并在达到模型特定的复杂门槛后完全崩溃(准确率为零)。」即使提升运算资源也无法突破这一限制。
「思考幻觉」背后
这份研究也为苹果过去相对保守的 AI 布局提供了一些线索。 尽管Apple Intelligence已于WWDC推出,但相较于谷歌、Samsung等对AI功能大量前置于装置中的积极策略,苹果明显采取不同方向。 这可能说明苹果为何在 LLM 与 LRM 热潮中始终维持距离——因为他们早已看见这些模型的思考极限。
这也呼应了研究中一段颇具哲思的总结:「AI 模型在数学与程序领域表现出色,但面对真正复杂问题时,它们展现出的,其实只是『思考的幻觉』。」
AGI 路漫漫
这项研究对于AGI乐观主义者而言可谓一记警钟,却也不代表AI无法推理。 正如 AI 专家Gary Marcus 在其网志指出:「普通人类在面对 8 层河内塔时也会失误。」这项研究虽未对比人类在同样问题上的表现,但至少点出目前模型的瓶颈与错觉。
Gary Marcus 进一步评论:「这份报告显示,无论你如何定义 AGI,LLM 目前仍无法取代传统的、经过良好定义的算法。」AI 不是万能的解答,但也不是全然无用,它只是还在学习,还没能做到真正思考。